In this rolling set of tips, I am sharing best practices and tricks to recognize text in PDF files using OCR in Adobe Document Cloud solutions.
- First tip has to be about the wonder called OCR! You can make your scanned images searchable by running OCR on them. Also, you can extract text from ‘image PDFs’ by doing so.
- Before you scan a whole lot of documents to OCR later, scan one paper at different settings and run OCR to see how the results are. Use the settings that gives you the least number of OCR suspects.
- To get the best results from OCR, use ClearScan. It generates smaller file sizes and looks better at a given DPI. For an in-depth description, see this article.
- When scanning documents customize the options to improve the quality of the scan and hence the quality of OCR. The settings I find useful are highlighted in the following screenshot. See this help article for more details.
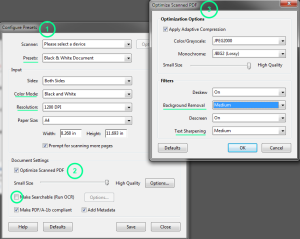
- Create as high quality scan as possible. Expect a good OCR if the image is 300 dpi or better. 600 dpi is good enough for most common purposes.
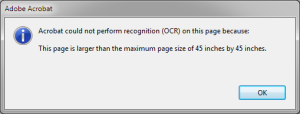
- Acrobat cannot OCR a page that is more than 45 inches in any one direction.
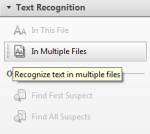
- You can add files other than PDF documents by selecting ‘In Multiple Files’.
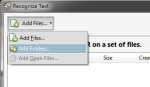
- You can run OCR on an entire folder by selecting ‘In Multiple Files’ and then ‘Add Folders’.
- You can disable OCR when scanning files. You may want to do so, when scanning many files and you have limited computing power! In the Configure Presets dialog for scanning, deselect ‘Make Searchable (Run OCR)’.
- If you have a choice, do not use text over bright or dark graphics in the source to be scanned. Such text is not recognized properly during OCR, as the contrast between the text and the background is not high enough.
- To enhance contrast, and hence the probability of a good OCR, turn on the darkness of the text and the lightness of the background to maximum, while scanning. Also, use a black and white setting, instead of color or grayscale scan.
- Make sure the printed paper is lying flat on the scanner bed and aligns with the edges of the bed. Former may lead to folds and hence distorted text in the scan. Latter may lead to text at an angle in the scan. Both types of scans are not a good source to run OCR on.





More Acrobat and OCR resources:
Help and support page for official content: https://helpx.adobe.com/acrobat.html
Acrobat user community: http://acrobatusers.com/
Share as comments, the OCR tips from your experience.

Nice blog about Optical Character Recognition (OCR).
{removed a backlink to myknown dotcom}
LikeLike